DreamVVT: Mastering Realistic Video Virtual Try-On in the Wild via a Stage-Wise Diffusion Transformer Framework
Tongchun Zuo1*, Zaiyu Huang1*, Shuliang Ning1, Ente Lin2, Chao Liang1 Zerong Zheng1 Jianwen Jiang1 Yuan Zhang1, Mingyuan Gao1†, Xin Dong1†,1Bytedance, 2Shenzhen International Graduate School, Tsinghua University *Equal contribution,† Corresponding author
Abstract
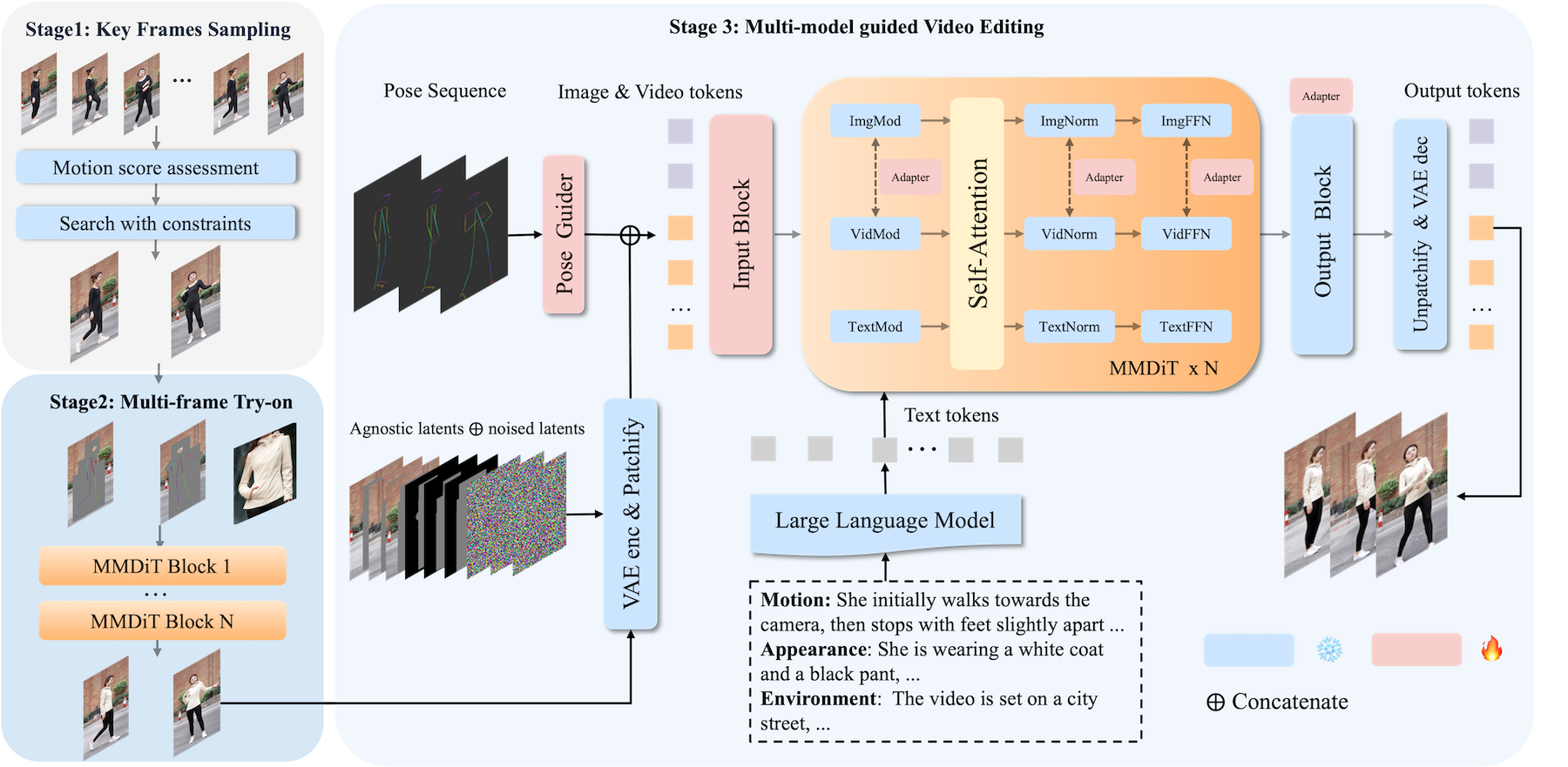
Video virtual try-on (VVT) technology has garnered considerable academic interest owing to its promising applications in e-commerce advertising and entertainment. However, most existing end-to-end methods rely heavily on scarce paired garment-centric datasets and fail to effectively leverage priors of advanced visual models and test-time inputs, making it challenging to accurately preserve fine-grained garment details and maintain temporal consistency in unconstrained scenarios. To address these challenges, we propose DreamVVT, a carefully designed two-stage framework built upon Diffusion Transformers (DiTs), which is inherently capable of leveraging diverse unpaired human-centric data to enhance adaptability in real-world scenarios. To further leverage prior knowledge from pretrained models and test-time inputs, in the first stage, we sample representative frames from the input video and utilize a multi-frame try-on model integrated with a vision-language model (VLM), to synthesize high-fidelity and semantically consistent keyframe try-on images. These images serve as complementary appearance guidance for subsequent video generation. In the second stage, skeleton maps together with fine-grained motion and appearance descriptions are extracted from the input content, and these along with the keyframe try-on images are then fed into a pretrained video generation model enhanced with LoRA adapters. This ensures long-term temporal coherence for unseen regions and enables highly plausible dynamic motions. Extensive quantitative and qualitative experiments demonstrate that DreamVVT surpasses existing methods in preserving detailed garment content and temporal stability in real-world scenarios.
Try-on Show Time
High-fidelity garment detail preservation under complex motion
* DreamVVT enables virtual try-on of complete outfits—including tops, bottoms, skirts, shoes, socks, and more. If a user uploads only a top, the model can automatically generate and match appropriate bottoms and footwear to complete the outfit. This capability is not available in previous methods.
* DreamVVT is capable of handling complex human motions, including runway walks and 360-degree rotations, with high fidelity in garment detail preservation and robust temporal consistency.
High-fidelity garment detail preservation in challenging scenarios
* DreamVVT is capable of enabling virtual try-on in videos featuring subjects within complex static or dynamic environments.
High-fidelity garment rendering under challenging camera dynamics
* DreamVVT can preserve temporal consistency and high-fidelity garment details, even when the input video features challenging camera movements and prominent scene transitions.
Generating plausible physical dynamics during garment interactions
* DreamVVT can generate realistic physical dynamics in scenarios involving garment interactions, for example, inserting hands into pockets or interacting with soft clothing materials.
Outfitting cartoon characters in highly demanding scenarios
* Even more interestingly, DreamVVT is capable of outfitting cartoon characters with real-world garments, even in highly demanding scenarios involving unrestricted subject poses or camera movement and dynamic scenes.
Ethics Concerns
The images and audios used in these demos are from public sources or generated by models, and are solely used to demonstrate the capabilities of this research work. If there are any concerns, please contact us (dongxin.1016@bytedance.com) and we will delete it in time.
Bibtex
@article{DreamVVT2025,
title={DreamVVT: Mastering Realistic Video Virtual Try-On in the Wild via a Stage-Wise Diffusion Transformer Framework},
author={Tongchun Zuo, Zaiyu Huang, Shuliang Ning, Ente Lin, Chao Liang, Zerong Zheng, Jianwen Jiang, Yuan Zhang, Mingyuan Gao, Xin Dong},
journal={arXiv preprint arXiv:2508.02807},
year={2025}
}